オンラインAI自習教材ガイド
人工知能を実現する方法として,今までいくつかの方法が開発されてきました.
たとえば,「全ての人間は,死ぬ」,「ソクラテスは人間である」と教えると,
「ソクラテスは,死ぬ」と答えるプログラムがあるとします.
こうしたプログラムは,知的な振る舞いをするため,人工知能と呼べるかも知れません.
こうしたプログラムにいろいろな知識を教えると,
「とある病気において,患者が死ぬかどうか」を答えてくれるプログラムが実現するかも知れません.
しかし,人工知能の長い研究の結果,明らかとなったのは,
そうしたプログラムが実用的な動作をするようになるまでには判断の根拠となる膨大な医学知識を整備する必要があるという点でした.
そして,医学知識の理解にはより一般的な知識の整備も求められることから,
その編纂に要するコストも膨れ上がり,およそ実用的でない水準となることが明らかとなりました.
こうして,期待されたほど実用的なアプリケーションが実現しなかったことから,
人工知能技術への関心は長らく停滞することになりました.
その後,人工知能が再び脚光を浴びるようになった背景には,いくつかの技術革新がありました.
まず,コンピュータが知的な振る舞いをする上で必要になる知識を人間が教えるのではなく,
問題を単純化することによって,機械が自ら学ぶことが可能となりました(機械学習).
また,人間の脳に含まれる神経網をモデルとしたニューラルネットワーク技術が発展し,
様々な実用的なアプリケーションが実現しました(いわゆるディープラーニング).
さらに,コンピュータの性能一般が向上したことに加えて,
機械学習やディープラーニングに求められる計算に特化した演算回路(GPU)が安価に入手可能となりました.
以上の結果,人工知能技術が,再び社会の注目を集めるようになりました. コンピュータ囲碁が,人間のトッププロに勝てるようになったことを聞いた方もおられるでしょう. 自動運転車や医療用人工知能についてのニュースも,数多く聞かれます. そうした現在の人工知能技術の核にあるのが,与えられたデータから法則性を学びとる,機械学習と称される一連の手法です. このページでは,人工知能について自習してみたいとお考えの方のために,最適な教材を探り当てるお手伝いを試みます
AIの中に機械学習という分野がありますので,その典型的な例として「回帰」の問題を考えてみましょう
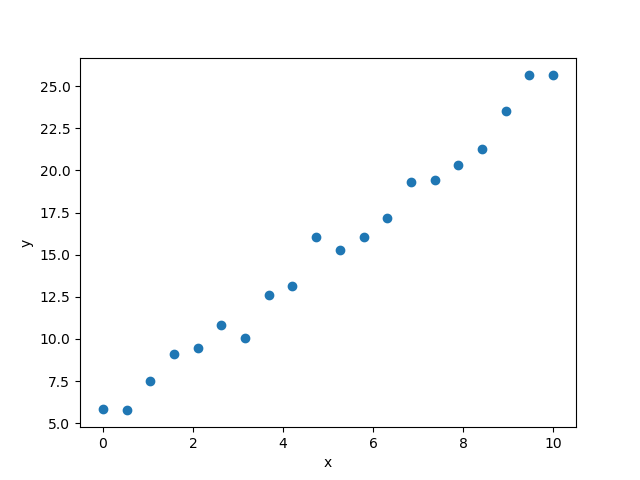
2つの実数の組のデータが $\{(x_1,~ y_1),~ (x_2,~ y_2),~ \cdots,~ (x_n,~ y_n)\}$ の$n$個あるとします. $x$を説明変数,$y$を目的変数といいます. これらのデータの分布が右の図のようになっていたとします. この図をみると,データを直線であてはめることができそうです. つまり,データの背後に比例関係という「法則」がありそうです.
$\displaystyle\quad L=\sum (wx_i+b-y_i)^2\qquad\qquad$ (1)
が最小になるという条件を採用します. $L$を$w$と$b$のの関数と考えると,$L$が最小(極小)になる
$\displaystyle\quad \frac{\partial L}{\partial w}=0\qquad\qquad$ (2)
$\displaystyle\quad \frac{\partial L}{\partial b}=0\qquad\qquad$ (3)
という条件から,$w$と$b$の連立方程式
$\displaystyle\quad (\sum x_ix_i)w + (\sum x_i)b - \sum x_iy_i=0\qquad\qquad$ (4)
$\displaystyle\quad (\sum x_i)w + nb - \sum y_i=0\qquad\qquad$ (5)
が得られ,これを解くと
$\displaystyle\quad w=\frac{n\sum x_iy_i - \sum x_i \sum y_i}{n\sum x_i^2-(\sum x_i)^2}\qquad\qquad$ (6)
$\displaystyle\quad b=\frac{n\sum x_i^2 \sum y_i - \sum x_i \sum x_iy_i}{n\sum x_i^2-(\sum x_i)^2}\qquad\qquad$ (7)
となります.
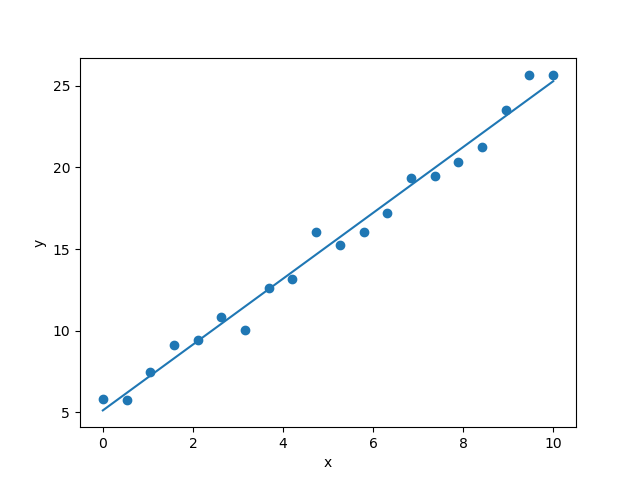
求めたパラメータを用いて直線を引くと右の図ようになります. 以上の方法を最小二乗法といい,パラメータが解析的に求まりました. より複雑な問題の場合,「勾配法」を用いて損失関数を最小化しパラメータを決定します.
最後に統計学との関連を述べておきます. 実測値と予測値のずれ$\epsilon_i = y_i-wx_i-b$が平均$0$,分散$\sigma^2$の正規分布
$\displaystyle\quad P(\{y_i\}|\{x_i\},~ w,~ b)=\frac{1}{(\sqrt{2\pi \sigma^2})^n}\exp(-\frac{1}{2\sigma^2}\sum (y_i-wx_i-b)^2)\qquad\qquad$ (8)
に従っているものと仮定します. これは,モデルパラメータが与えられたときにデータが得られる条件付き確率であり,「尤度」といいます. 先ほど設定した損失関数最小の条件は尤度が最大になる条件と一致します.
誤差の2乗和を求めています
(高校数学B 数列の和)
損失関数の偏微分を計算しています
合成関数の微分の理解も必要です
(大学初年度 微分積分学)
連立方程式を解いています
(大学初年度 線型代数学)
PythonライブラリのNumpyを読み込み, $0\le x\le 10$の範囲を$20$等分した$x$の座標を配列として確保し, 各点で$y=2x+5$を計算し さらに平均0標準偏差1の正規分布に従う乱数を $y$に加えています.
「回帰」の問題を概観しましたが,ここに出てきた考え方は機械学習・深層学習において 基本的かつ重要なものです. 例えば,深層学習などのニューラルネットワークを用いた「学習」では, 「損失関数」を最小にすることでニューラルネットワークの重みパラメータを調節します. このとき用いられる「勾配法」を「誤差逆伝播法」といいます.
教材に取り組まれる際に,これらのキーワードを手がかりにされるとよいでしょう.

価格:1512円
263ページ
出版社:KADOKAWA
ISBN:4040800206
発売日:2015.3.11


価格:3996円
600ページ
出版社:オライリージャパン
ISBN:4873117380
発売日:2015.12.1

価格:2894円
416ページ
出版社:ソーテック社
ISBN:4800711673
発売日:2017.5.24

価格:2808円
208ページ
出版社:インプレス
ISBN:4295003182
発売日:2018.2.16
キーワード:TensorFlow,CNN,RNN

価格:3672円
320ページ
出版社:オライリージャパン
ISBN:4873117585
発売日:2016.9.24
キーワード:Python,パーセプトロン,ニューラルネットワーク,CNN

価格:2700円
256ページ
出版社:ソシム
ISBN:480261179X
発売日:2018.10.26

価格:2894円
400ページ
出版社:翔泳社
ISBN:4798144983
発売日:2018.1.24
キーワード:Python,数学,回帰,分類,ニューラルネットワーク,教師なし学習