医療用人工知能の作り方
~研究開発の中心となるデータ作成の実際~
この記事は15分で読めます
概要
機械学習を用いた人工知能に開発において、学習データは必要不可欠なものとなってきました。この学習データの生成には人間による作業が必要不可欠あり、学習データの種類によってはその作業に高度な専門的な知識を要求します。そんな中、医療用データを用いて学習を行なう医療用人工知能は学習データの生成に医師の協力が必要となることがあります。
ところが、このデータ生成には膨大な単純作業が含まれ、医師の多くがそういった作業を好みません。こうした状況は医療用人工知能の開発を遅らせる大きな原因となり得ます。こうした作業に関して医師の理解を得られれば、医療用人工知能の実用化に向けて大きな一歩となります。
1.人工知能と機械学習
近年、人工知能が急激に進歩したことで、関連技術があらゆる領域で話題になっています。顔認識技術がスマートフォンなどのセキュリティ分野に応用され、記者の代わりに記事を書き、症状から疾患を提示して医師の手助けをするようになってきました。人間の知能を再現するという人工知能の試みは長い年月を経てようやく形になってきました。こうした人工知能の成長を支えているのがディープラーニングを始めとする機械学習です。
今までは人工知能の認識・判断・行動に関わるあらゆるルールを人間が自ら教えていました。しかし、人間が直接教えられることには限界があり、特に人間が無意識に行っている感覚的なタスクである画像認識や音声認識などの領域では長らく壁にぶつかっていました。それがディープラーニングによって壊れたのです。
大きく進歩した人工知能による認識能力によって人工知能は改めて注目を集めるようになり、様々な応用に期待がかかるようになってきました。その一方で、人工知能がどのように学習し、成長しているかという点についてはよく理解されていません。そこで、画像認識システムの学習プロセスを例に挙げ、機械学習の特性について簡単に解説していきます。
2.画像認識を行なう人工知能の開発
人工知能の開発と一口に言っても様々なアプローチがあります。人工知能の目的と目的達成の手法、使われる技術によって開発方法は全く異なっており、全ての人工知能が同じプロセスで作られているわけではありません。今回、人工知能の応用技術の中でも社会に大きなインパクトを与えた「画像認識システム」における画像の学習プロセスについて紹介します。
機械学習には大きく分けて人間が学習データに正しい情報を付与する「教師あり学習」と正しい情報を付けない「教師なし学習」があります。ここでは学習効率に優れた教師あり学習について解説します。この場合、学習プロセスは「データの収集」「データへのラベル付け」「ラベル付きデータでの学習」「性能評価と改善」の4つです。性能評価で満足の行く結果が出ればこのプロセスは終了しますが、出なければアルゴリズムや学習方法に改善を加え、必要に応じて新たにデータ収集・ラベル付け・学習・評価を繰り返します。次に、各プロセスで何が行われているのかを細かく見ていきましょう。
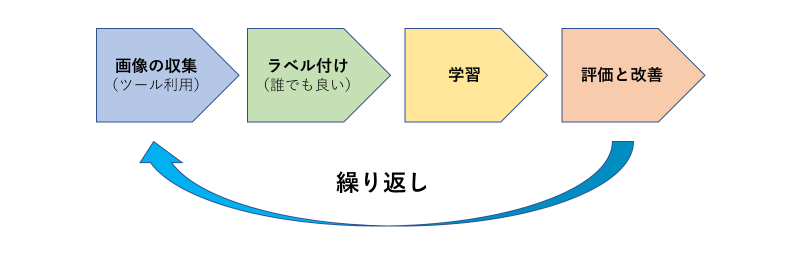
<データの収集>
まずは学習させたい対象の画像を収集します。人間の顔であれば人間の顔を、犬の画像であれば犬の画像を集めることになります。ここで収集される画像の枚数は時に数千万に及び、手軽に集められるものではありません。さらに、同じ人間の画像であっても角度・背景・光によって見え方が異なるように、全く同じ物体の画像であっても、バリエーションに富んでいることが望ましいのです。
当然ながら「どこからそんなに沢山の画像を集めてくるか」という点が問題になります。一昔前であれば、この段階で画像が集められず人工知能の性能は頭打ちになっていたところですが、今ならインターネットがあります。キーワードで検索すれば大量の画像がヒットする上に、動画を使えば1つの動画から同じ対象の角度の違う画像を複数枚入手できるため、「人間や動物の画像」であればさほど学習用データの収集には困らなくなりました。
<ラベル付け>
ところが、こうして得られたデータはそのまま学習に使うことはできません。データを集める際に人間が一枚一枚選んでいた場合はともかく、通常はより多くのデータを一度に収集できるようにするためにデータ収集用のプログラムを作り、そのプログラムにデータを集めさせます。そのプログラムはあくまで「特定のキーワードで得られた画像を全て収集する」もしくは「特定のキーワードで検索した動画の中からランダムに画像を抽出する」などのタスクを行なうだけのものであることが多く、全く関連性の無い画像も多数混ざっています。
そのため、収集した画像は人間が目で見て分類していかなければなりません。人間の顔を認識させたいのであれば、人間の顔が含まれている画像に「人間の顔」というラベルを付け、犬を識別したいのであれば犬の含まれている画像に「犬」というラベルを付けていきます。この作業は人間の顔や犬を識別出来る人間なら誰でも出来る極めて単純な作業ですが、それを1人で何千何万と行なうため、ここでも効率化のためにプログラムを組むことが多いです。
例えば、犬を識別するために、画像と一緒に「犬である」「犬ではない」と書かれたボタンが表示され、クリックすると次が表示されるようなプログラムを作れば、人間が行う作業は画像を見てマウスやキーボードを押すだけになります。単純作業でも、最低限の作業で済むプロセスを作ることで時間と労力は最小限に抑えられます。
<データでの学習>
退屈なラベル付けの作業が終わると今度はそれを使って人工知能に画像を識別するための学習を施します。この際、ラベルの付け方によって成果は大きく変わってきます。例えば、「犬である」「犬ではない」というシンプルなラベルしか貼っていないのであれば、人工知能が学習するのは犬か犬ではないかだけで、犬の種類までは識別しません。もし、「犬であるかどうか」に加えて「犬の種類」も加えれば犬の種類も学習できますし、犬ではないものに「人」や「猫」を加えれば、そのデータを使って人や猫の識別について学習させることもできるでしょう。
そして、人工知能の学習時間は画像の枚数・アルゴリズム・コンピューターの性能にもよりますが、学習プロセス全体から見てそれほど多くの時間はかかりません。場合によっては一瞬で終わります。人工知能の開発プロセスにおいて「学習」は重要なプロセスであることに変わりありませんが、手間と時間がかかるのはそれ以外のプロセスなのです。
<性能評価と改善>
学習が終わった後に行なうのは性能評価です。ここでは、学習用のデータとは別に作っておいたテスト用のデータを使って検証します。人工知能は学習を経て「犬だと思った画像」「犬ではないと思った画像」を出力します。こうして出力されたデータを人間がチェックし、その精度などを評価します。
ここで良い結果が出ても、悪い結果が出ても、評価と改善のプロセスは重要です。以前と比べて良くなった原因、悪くなった原因を推察し、アルゴリズムにさらなる改良を加えていきます。もし機械学習のアルゴリズムではなく学習データに問題があった場合は、次に収集する画像データの集め方やラベルの付け方についても検討していかなければなりません。場合によっては、画像をゼロから集め直すこともありますし、ラベルを最初から付け直すこともあります。
ここまでで画像認識システムの学習プロセスはとりあえず終了です。しかし前述の通り、必要に応じて何度も何度も繰り返されます。作り始めたばかりのシステムであれば、繰り返す回数は1回や2回ではなく、場合によっては何十回と繰り返すことになります。そのたびに学習データを集め直し、ラベルを付けるわけですので、これは途方もない労力を伴うプロセスであることが分かるでしょう。
3.医療用人工知能で同じことができるのか
前述の画像認識システムのプロセスは、画像・文字・音声などの認識タスクを行なう人工知能の多くで共通しています。この学習プロセスをきちんと回すことができれば、一定水準の認識タスクを実行できる人工知能が完成するでしょう。
しかし、一見単純そうに見える学習プロセスにも大きな問題があります。学習に必要なデータが膨大なのです。データはインターネットから適当に拾ってくるだけでは不十分で、ラベル付けなどの作業によって学習に使えるデータに変えていかなければなりません。前述の画像認識システムのように「犬」を識別するだけの作業であればそれほど難しくはないでしょう。犬が何なんなのか認識してラベルを付けるだけであれば小中学生だって構いませんし、日本以外にもいくらでも依頼できる相手が存在します。
その一方で、認識するべき情報の「答え」が分かる人間が少ない場合には非常に厄介です。例えば、肺のレントゲン写真を見てその「答え」となる疾患を当てることができる人間は医師など医療の専門家だけに限られます。必然的にラベル付けの作業は経験豊富な医師に依頼せざるを得ませんが、こうした単純作業のために医師を確保し、医師に見合った高額な報酬を支払うことは容易ではありません。
問題は人手や費用が集めにくいだけに留まらず、医師であっても疾患があるかないかの判別は犬がいるかいないかという判別に比べて遥かに難解で、画像によってははっきりと断定できない「疑いがある」レベルに留まるようなケースも多いのです。開発者と作業者である医師間での基準に関する議論も欠かせないため、ラベルの判定基準ですら簡単には決められません。
医療用人工知能に限らず、人工知能の学習は学習に用いる情報の認識・理解に高度な専門知識が必要なケースになるほど難しくなります。しかも、医療用人工知能の場合は学習に使うデータが個人情報に関わるケースも少なくないため、インターネットで何でも集まる時代であるにかかわらず、データを集めることにも苦労します。そして、苦労して収集したデータにラベル付けをしようにも頼める医師もいなければ雇うお金もないのです。
医療用人工知能の開発が画像認識の人工知能のようには行かない理由はわかりました。では、実際に医療用人工知能のケースでどのような作業が行われるのかについて説明していきましょう。
4.文献のリファレンスを表示する医療用人工知能の開発
医療用人工知能にも様々な種類が存在し、中でも注目を集めているのが診断支援を行なう人工知能です。今までは医師にしか識別することができなかった様々な疾患を、画像を含む各種検査データや症状から自動で判別してくれるようになりました。これだけでも十分優れているのですが、もしこうした診断支援システムが疾患に関連する文献のリファレンスを上げてくれたらどれほど医師の仕事が楽になるでしょうか。
そこで、診断支援システムに文献のリファレンスを表示する機能を追加するとします。そのためには疾患別のリファレンスリストが必要となりますが、次々に増えていく膨大なリストを人力で整理するのは難しいでしょう。そこで文献を確認し、自動で整理してくれる分類用の人工知能を作ることにします。
この場合、膨大な医学文献を適切に分類するためのルールを人間の手で入力していくことは現実的ではないため、機械学習を用いて人工知能に自ら学ばせるのが現実的です。その際の学習プロセスは前述の画像認識システムの学習プロセスと殆ど変わりません。ただ、医療用人工知能であるため、各プロセスで必要となる作業が微妙に異なってきます。
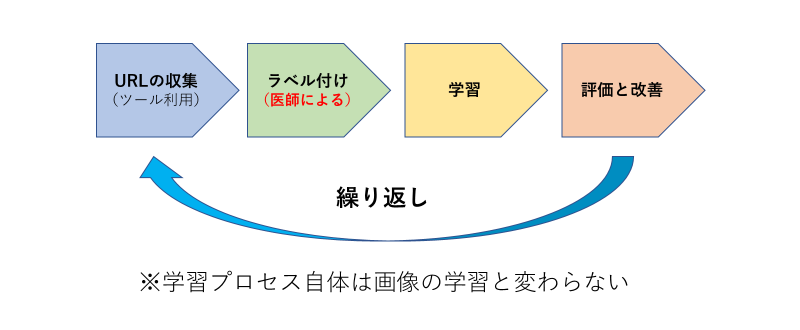
<データの収集>
まず、文献データの収集を行います。画像認識システムの学習と同様にこれも自動で行ないます。ただし、検索時のキーワードは疾患名であったり医学用語であったり、より専門性の高いものとなるため、ヒットする件数が少ないこともあれば無関係なものも少なくありません。また、今回はインターネットを使った文献の収集であるため、実際に収集するのはウェブページのURLとなります。URLにはWikipediaから公的機関の医療サイトまで含まれており、情報の形態は多岐に渡ります。画像認識システムの学習データのように一つの動画から複数の画像ファイルを入手することもできなければ、ヒットした画像ファイルそのまま集めれば良いというわけでもないので収集用のツールの開発も簡単ではありません。
<ラベル付け>
そうしてデータを収集した後は、URLのリンク先のウェブサイトを確認し、医療用の文献としてリファレンスリストに掲載する価値があるかをチェックすることになります。この時点では、キーワードでヒットしたURLが集められているだけであり、疾患の名前が入っているだけで無意味なURLもあれば、疾患とは全く無関係のURLも存在します。
分類用の人工知能には、まずこうした無価値な文献を可能な限り取り除いて貰う必要があります。価値のある文献かどうかの確認は専門知識を持った人間にしかできないため、この作業は医師に依頼します。ただ、医師に依頼するからといって実質的な作業内容が複雑になるわけではありません。タスクとしては極めて単純で、URLリストに含まれている文献を1つ1つ確認し、価値があるか無いかのラベルをひたすら付けていくだけです。
<データでの学習>
ラベル付きデータが完成したら、そのデータを使って分類用の人工知能が価値のあるデータだけを出力するように学習させます。この際、価値のあるデータだけではなく「不要」というラベルが付いたデータも同時に入力することが重要です。インターネット上に存在する文献には無数の種類があり、価値ある文献に似た無価値な文献も存在します。こうしたものも可能な限り正しく分類し、不要なデータを正確に「不要である」と分類できるようにならなければなりません。
<性能評価と改善>
学習完了後、改めて文献を分類させ評価します。価値あるデータが出てくれば良いのですが、そう簡単にはいきません。価値のあるデータとして主力されたものの中に含まれる無価値なデータがなぜ含まれたのかを分析し、アルゴリズムの改善やデータの収集・ラベル付けの改善に生かして行かなければなりません。この際、ラベル付けには「価値がある」「価値がない」だけではなく、「なぜ価値があるのか」「なぜ価値がないのか」についてのラベルもあることが望ましいでしょう。
分類プログラム自体は「価値がある」「価値がない」という分類しかしませんが、人間が評価・改善を行うためにより詳細なラベルが付いていることが望ましいからです。もちろん、この評価・改善プロセスで新たにラベルが追加されることもあればラベルが修正されることもあり、収集・ラベル付け・学習・評価を繰り返すことはより大きな意味を持ってきます。
5.医師による医学文献のチェック作業 -ガイドラインの策定-
ここまでの解説で、内容に微妙な違いはあれども、大まかなプロセスは画像認識システムの学習と医療用人工知能でさほど変わらないことは分かって頂けたと思います。ただ、小さな違いが大きな問題を生むことがあります。それは「ラベル付け」の工程です。分類用人工知能に出力してもらいたいのは「医師がリファレンスとして読む文献として価値のあるもの」であり、その答えを知っているのは医師だけです。医学的な知識がない人間には頼めません。そのため、医師に文献が使えるか使えないかのラベル付け作業をしてもらうことになります。
もう少し具体的に掘り下げてみましょう。まず、医師は大量のURLリストを渡され「有用な文献とそうでない文献を分けてください」と依頼されます。ところがすぐに、このケースで言う「有用な文献って何だ」という話になります。つまり、判定基準に関する情報が不足しているのです。すぐにラベル付けに関するガイドラインの策定が必要になります。画像認識システムの学習のように「犬である」「犬ではない」という話であれば簡単ですが、医療に関わるデータの分類はそう簡単な話ではありません。
例えば、「Wikipediaなどのサイトでは、医学的に有用な情報はあるものの信頼できるとは言えない文献がある。これは価値があるといえるのか?」「研究領域では価値があるものの、臨床現場では価値のない論文はどうなるのか?」などの疑問が生まれます。こうした疑問に対し、人工知能の開発者は「明らかに不要と思われるものだけを除外したい。そのため、用途によっては価値がある文献は価値があると判定して欲しい」という回答を返します。
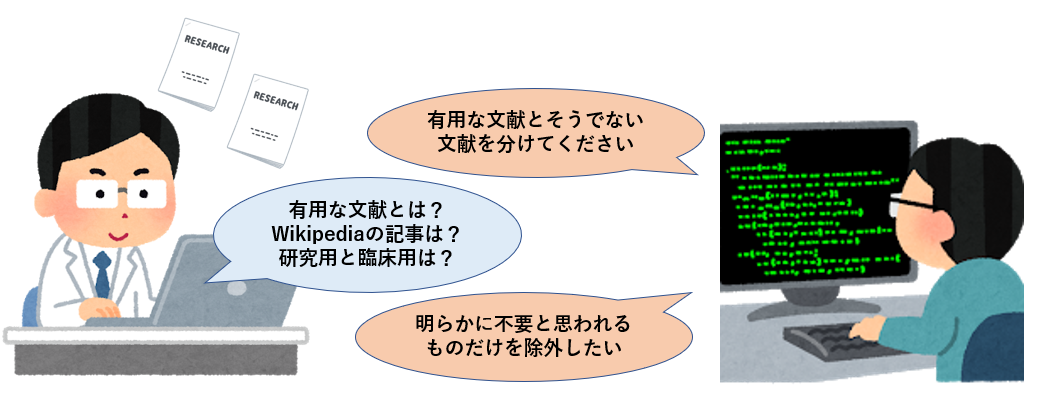
最初にURLを数件チェックしただけでもこれぐらいの質疑応答が行われます。こうしたやり取りを経てようやく暫定的なガイドラインが作られるのです。当然ながら、素人に「研究領域で価値のあるもの」と「臨床現場で価値のあるもの」の区別はつきません。今回のケースでは両方共価値があるとされたましたが、臨床現場だけで利用するものであれば区別する必要があったかもしれません。
6.医師による医学文献のチェック作業 -ラベル付け作業-
暫定的なガイドラインが完成してようやく実作業に入ります。ただ、膨大なURLを1つ1つ開いてチェックするのではどれだけ時間がかかるか分かりません。そのため、画像認識システムの学習時と同様に、チェック作業を効率化するツールが作られます。今回のケースでは、URLをいちいち開くのは手間なので、リンク先のキャプチャー画像と一緒にラベル選択のボタンが表示されるツールが作成されました。これによって医師はいちいちURLを開く必要がなくなり、少なくともキャプチャー画像のみで判断できるレベルのデータであれば簡単に分類できるようになりました。

しかし、ツールを用いたとしても単純作業がひたすら続くことには変わりありません。医療関係者向けの公的機関のサイトで、内容的にも明らかに価値があるだろうと見ただけで判断できるケースもあれば、リンク先に飛び、文献をしっかり読まなければならないケースもあるため、集中力の必要な作業が続きます。さらに、その過程で先に作成した暫定的なガイドラインでは対応できない問題にも遭遇します。
例えば、「疾患をまとめた便利なリストが含まれているケース」「医学的に価値があるが、そもそも動物に関する疾患であるケース」「医学的な文献だけど情報不足なケース」「英語で書かれていない文献」などです。これらの文献は状況によっては価値を持つ文献であり、一概に無価値と分類するのは避けたいとこです。そこで、人工知能の開発者はラベル付けのガイドラインを改定し、「リスト」「ミスマッチ」「情報不足」「非英語」「その他」などのラベルを追加しました。
それに合わせてツールを修正し、合わせてツールの使い勝手についても医師のフィードバックを受け、ツールについてもより効率的に作業できるように改善していきます。こうしたやり取りを繰り返しながらガイドラインを確定することで、ようやく安定して作業が進むようになります。
7.医療用人工知能の完成に一歩近づいた
分類用の人工知能はこうして分けられた文献を使って「価値がある文献」が何なのか学習していきます。医学生なら、分類された文献を何件か読めば「価値がある」とされる基準を理解できるかもしれませんが、人工知能ではそうはいきません。何千何万もの文献を読みながら、少しずつ学習していきます。また、何千何万もの価値があると判定された文献の中に大量に実は「価値のない文献」が混ざっていると学習が進まないため、ラベル付けの質は重要です。単純作業だからと十分な知識のない人間に頼むと、せっかく集めたデータが無駄になってしまいます。人工知能の性能向上において、このラベル付けの作業は非常に重要な作業と言えるでしょう。
ラベル付けを終え、データを使って学習させ、評価と改善が終われば医療用人工知能が完成するかというとそうは行きません。評価の内容次第では新たに文献を集めて同じ工程を繰り返す必要があります。そうして何とか分類用の人工知能が価値ある文献を見つけ出してくれるようになったとしても、これは診断支援システムに搭載する追加機能であるため、実際にどのように表示するのか、表示する順番はどう選定するのか、関連のある文献をどう絞り込むのかなど、問題は山積しています。
診断支援システムが鑑別と合わせて文献を表示し、それが医師の業務に役立つようなレベルに達するまでの道のりはまだまだ遠いです。しかし、医療用人工知能が現場で使えるようになり、患者に治療に役立つようになるためには、この長い道のりを少しずつ進んでいかなければなりません。
8.まとめ
機械学習を用いた人工知能の開発において、学習用データは必要不可欠です。しかし、学習用データの作成過程で人間の手が必要になり、それが膨大な単純作業であることはあまり認識されていません。また、学習に用いるデータによってデータの加工作業を行う人間に求められるスキルが違い、それによってこの単純作業の担い手が限られ、人工知能の開発に大きな影響を与えることもあまり知られていません。
残念ながら、医療用人工知能の学習では医師によるデータ加工が必要であるにも関わらずこの作業の重要性が正しく理解されておらず、協力者を得ることが難しくなっています。データの加工作業自体は非常に単調ではあるものの、こうした地道な作業が医療用人工知能の実用化には必要不可欠です。本記事を通じて、医療用人工知能の開発には医師の協力が非常に重要である点をご理解頂ければ幸いです。